 AI論
AI論 地頭がいいとは何か——生成AI時代に問い直す
「地頭がいい」という言葉はよく使われる。だが、その定義は驚くほど曖昧だ。頭の回転が速い物覚えがいい勉強ができる多くの場合、この程度の意味で使われている。しかし、それは本当に「地頭」なのだろうか。地頭がいいとは、今までにないものを紡ぎ出せる力...
AI論  LLM高速化アルゴリズム
LLM高速化アルゴリズム  LLM高速化アルゴリズム
LLM高速化アルゴリズム 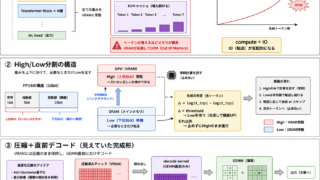 LLM高速化アルゴリズム
LLM高速化アルゴリズム 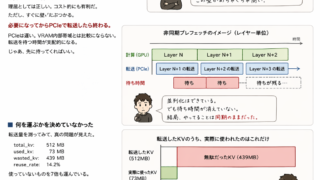 LLM高速化アルゴリズム
LLM高速化アルゴリズム 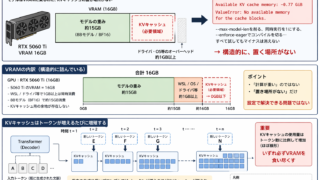 LLM高速化アルゴリズム
LLM高速化アルゴリズム