
全部読む必要あるのか?
全部読む必要あるのか?
LLMは計算で遅いわけじゃない。
HBMからの読み出しで死んでる。
Transformer自体は速い。
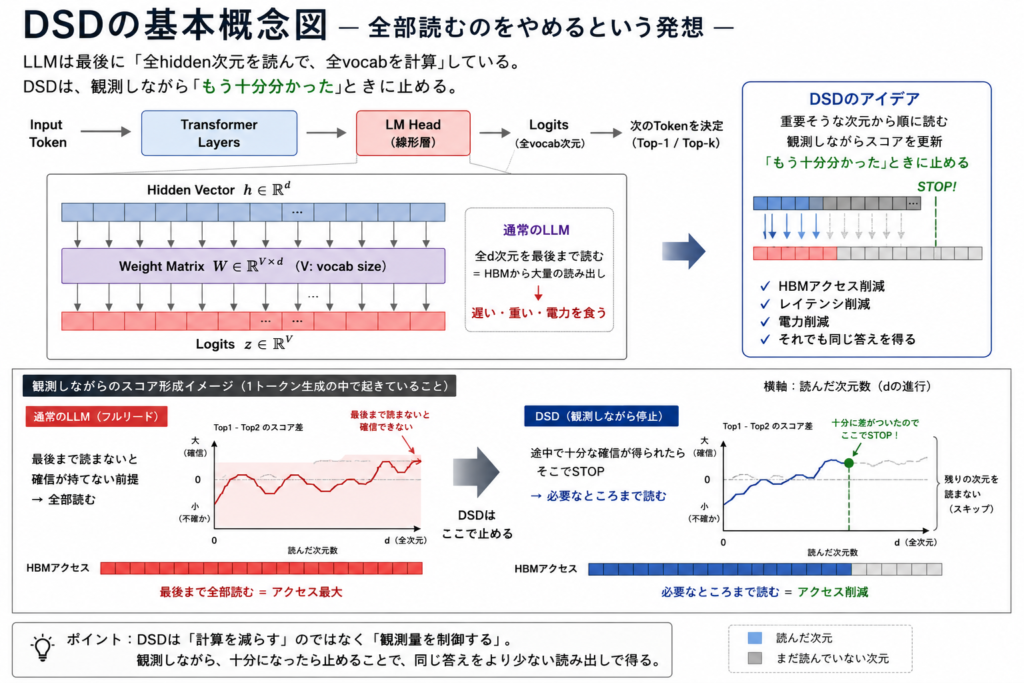
問題は最後。
LM Head。
hiddenを全部読んで、
全vocabに対して最後まで計算する。
しかも毎token。
だから重い。
だから最初に思った。
全部読む必要あるのか?
目次
- 普通のLLMは最後まで止まらない
- 最初の目的は省電力だった
- DSDの最初の発想
- でも実際にやると、全然止まらなかった
- 実hiddenを見始めた
- ここで意味が変わった
- DSDは計算削減ではない
- まだ、この時点では分かっていなかった
普通のLLMは最後まで止まらない
普通の推論はこうなっている。
- hiddenを生成
- 全次元を読む
- 全vocabを計算
- logits生成
- softmax
途中で「もう十分分かった」がない。
最後まで読む前提。
これ、最初は単純に無駄に見えた。
例えば:
- the
- of
- 句読点
- 定型token
かなり早い段階で、もう候補が固まっているように見える。
なのに最後まで読む。
全部。
毎回。
最初の目的は省電力だった
この時点では、trajectoryとか考えていない。
目的は単純。
- HBMアクセス削減
- レイテンシ削減
- 電力削減
だけ。
特にエッジ。
介護PoCをやっていると、すぐ限界が来る。
「動く」では足りない。
待てない。
電気を食いすぎる。
GPUを積めない。
ここで初めて、
推論はFLOPSじゃなく、memoryで死んでる
という感覚になった。
DSDの最初の発想
発想自体はシンプルだった。
- 重要そうな次元から読む
- 部分的にscore更新
- もう十分なら止める
ただそれだけ。
この時点では、
「stop技術」
のつもりだった。
runtime dynamicsを観測するつもりではない。
でも実際にやると、全然止まらなかった
最初はrandom tensorで試した。
止まらない。
全然止まらない。
そこで最初に思ったのは、
実装ミスか?
だった。
違った。
random tensorでは、candidate collapseが起きにくかった。
つまり、候補が早期に圧縮されない。
後から考えると当然だった。
情報が均一だから。
でもこの時点では、まだ分かっていなかった。
実hiddenを見始めた
TinyLlamaをGPUで動かした。
実hiddenをそのまま観測した。
ここで初めて空気が変わった。
止まった。
実際のログ。
baseline top1:
Japan
STOP!
stop_dim: 1433
skip ratio: 0.30029296875
top1:
Japan
match: True30%近くhidden readを削減しても、Top1が一致した。
ここで初めて、
これは存在する
になった。
ここで意味が変わった
最初は、
どこで止められるか
を見ていた。
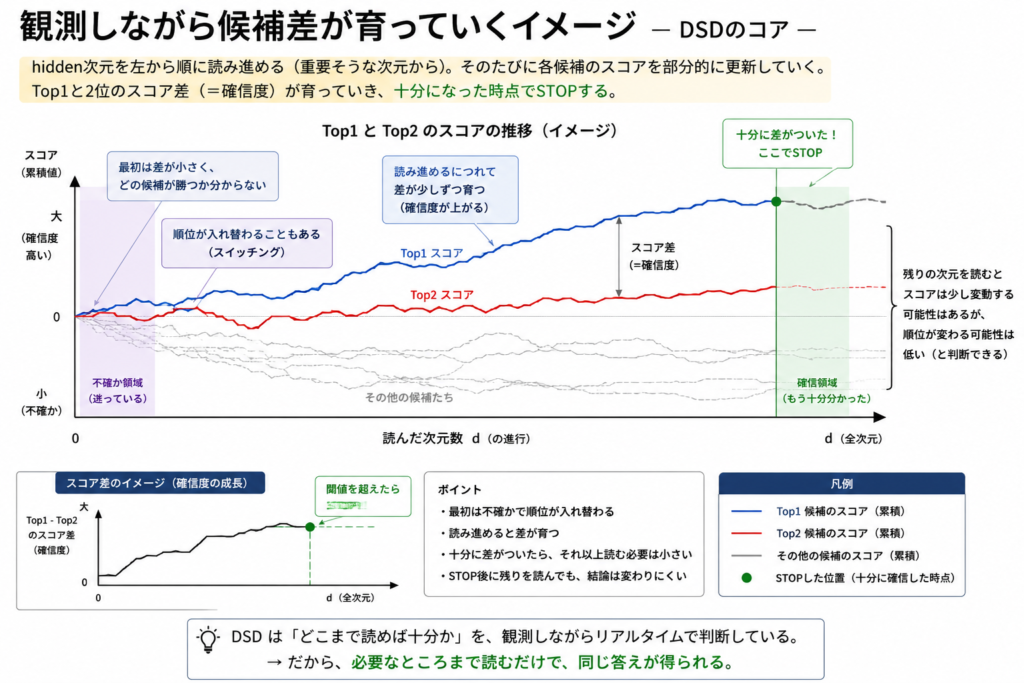
でもruntimeを観測していると、別のものが見え始めた。
- collapse
- switching
- oscillation
- recovery
候補が動く。
迷う。
固まる。
また揺れる。
つまり見えていたのは、
推論結果
ではなかった。
推論の形成過程
だった。
DSDは計算削減ではない
ここでDSDの意味が変わった。
DSDは、
「計算を減らす」技術ではなかった。
「観測量を制御する」技術だった。
全部読むのをやめる。
必要なところまで読む。
十分に分かったら止める。
そして、その途中過程そのものがruntime observableになった。
まだ、この時点では分かっていなかった
この時点ではまだ、
- なぜ実hiddenでは止まるのか
- なぜrandom tensorでは止まらないのか
- なぜ候補がcollapseするのか
分かっていなかった。
でもruntimeでは、確かに何かが起きていた。
そして後から振り返ると、この時点で既に、trajectoryを見始めていた。


コメント