動いた、でも使い物にならない。
技術的には成功していた。でもPoCで撃沈。
介護現場に出入りしていて、記録が大変で本来の仕事である介護にかける時間を圧迫されている現場を見て、記録なら生成AIを使えば今よりも自動化できないかと思った。
医療介護はセキュリティ要件が厳しい。そのため、オンプレでLLMを動かせないかと思って作ったけど、遅すぎて実用にならなかった。
じゃあ速くするしかない、と思って色々試して、気づいたらLLMの高速化アルゴリズムを考えていた。特許も出願した。
どこで道を踏み外したのか、順番に書いていく。
まずローカルで動かそうとした
生成AIはど素人なんで、動かすためにはGPUが必要らしいというところから始まる。 RTX 5060 Ti というものを買った。BlackwellアーキテクチャのGPUだということは後で知った。 CUDAという言葉すら、当時は知らなかった。
買ってから気づいたが、このBlackwellには当時LLMに必要なCUDAの正式対応が出ていない。
ハードはある。ドライバも入る。でも動かない。 NVIDIAは新しいアーキテクチャを出しておいてソフトウェアスタックの対応を平気で後回しにする。 あるあるらしい。
仕方ないからAIに調べさせて、正式対応前に自力で動かした。
なんだかよくわからないけど、生成AIの言う通りに設定して、ようやくLLMを回せると思ったら、今度はKVキャッシュってやつで死んだ。
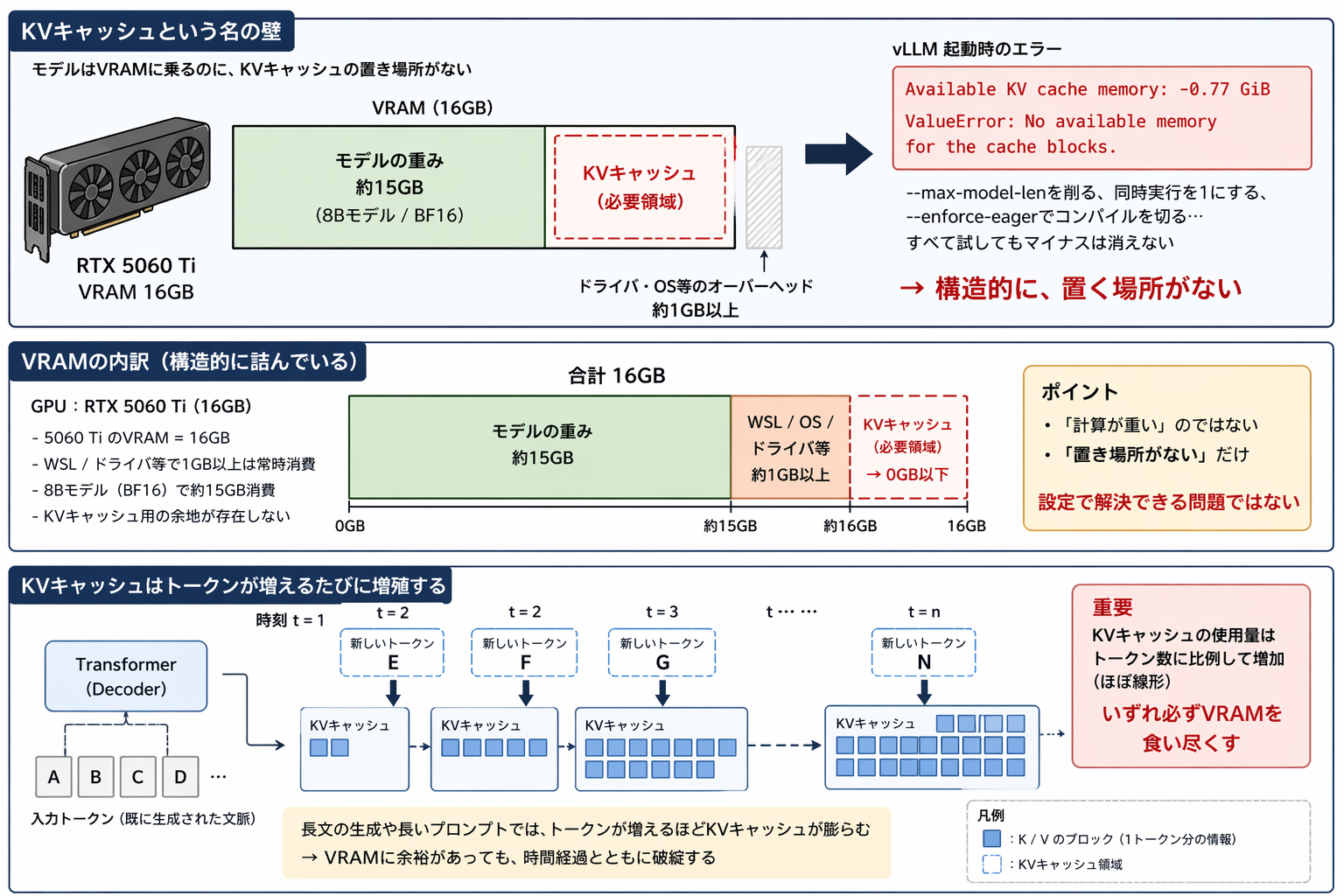
KVキャッシュという名の壁
vLLMというフレームワークで8Bモデルを読み込ませた。重みが約15GB、VRAMに乗った。ここまではいい。
Available KV cache memory: -0.77 GiB ValueError: No available memory for the cache blocks.
モデルは乗る。でもキャッシュが乗らない。

マイナスだ。KVキャッシュの置き場所がない。
–max-model-lenを削った。同時実行を1本に絞った。–enforce-eagerでコンパイルを切った。全部やった。
Available KV cache memory: -0.21 GiB
数字は少し改善している。でも本質は変わっていない。
ここで初めて、自分で構造を追った。 何が足りないのかではなく、何が成立していないのかを。
返ってきた答えで初めてわかった。 8BモデルをBF16で持つと約15GBになる。 5060 TiのVRAMは16GBだが、WSLとドライバで1GB以上は常に消える。
最初からKVキャッシュの置き場所がない。
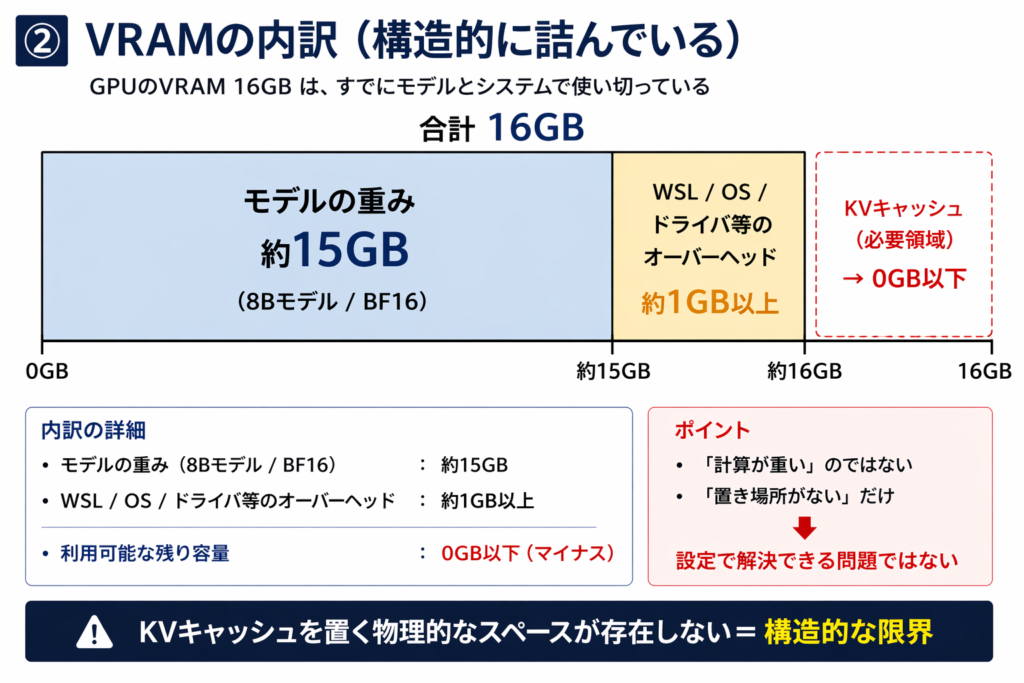
設定で解決できる問題じゃなかった。
ここで初めて気づいた。
LLMは計算が重いのではなく、メモリとIOの設計が破綻している。
CUDAバージョンという名の別の壁
次にCUDAのバージョンで詰まった。
nvidia-smiを叩くとCUDA 12.9と表示される。 vLLMの安定版はCUDA 12.4で動いている。 合わせようとすると別のエラーが出る。またAIに投げた。
ここでわかったことがある。
ドライバが本体で、コンテナはランタイムだけ借りる。
NVIDIAのドライバは後方互換がある。 ホスト側のCUDAがコンテナ側以上なら動く。 ホストが12.9でもコンテナが12.4なら問題ない。逆はダメだ。
これがわかれば話は単純だった。 DockerfileはCUDA 12.4で固定する。ドライバは最新を入れておく。それだけだ。
Zennの記事の大半は「このコマンドを打てば動きます」で終わっている。 なぜ動くかを書いていない。 AIと壁打ちしながら構造を理解することで初めて見えた話だった。
ここでようやく「動かすための前提」は揃った。
Swallow-MS 7Bで落ち着いた
8BはVRAMに収まらないのでSwallow-MS 7Bに切り替えた。 Mistralをベースに東京科学大学と産総研が日本語で継続学習したモデルだ。 FP16で約14GB、KVキャッシュに余裕が生まれた。
ここまでで、動かすことはできた。
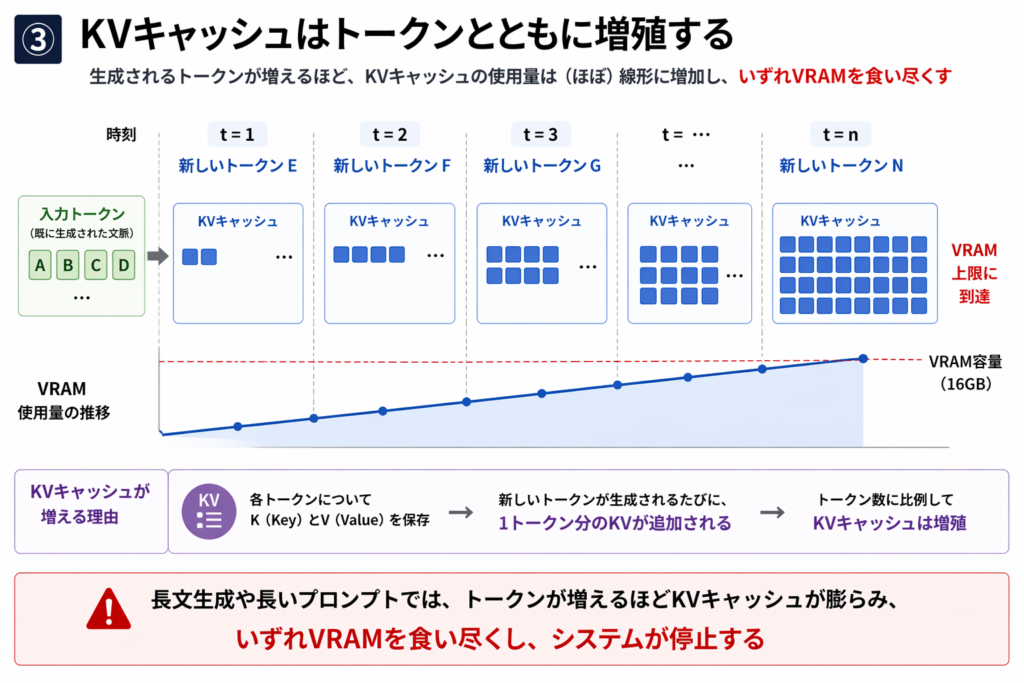
だが、問題は何一つ解決していない。遅すぎて使えない。
ただ当然このメモリ容量では早晩KVキャッシュがあふれるのは自明だ。 ここからまだ別の戦い、VRAM容量の削減との格闘が始まる。
ただ、ここまでやっていて、一つだけ引っかかっていたことがある。
メモリは確かに足りない。
でも、それ以上に違和感があった。
なぜ、ここまで全部を前提にしているのか。
この時点では、まだ言語化できていなかった。
ただ、「何かがおかしい」という感覚だけが残った。

コメント