
| 全部VRAMに乗せる前提を疑った──非同期プレフェッチという発想と、その限界 |
|---|
「なぜ全部乗せる必要があるのか」という問い
①では、Swallow-MS 7Bをなんとか動かすところまで辿り着いた。
とりあえず動く。出力もそれっぽい。
でも結論はシンプルだった。
遅すぎて使えない。
1トークン出すのに待たされる。
体感的に「対話にならない」レベルで遅い。
ここで一度、細かい最適化は全部やめた。
構造そのものを疑うことにした。
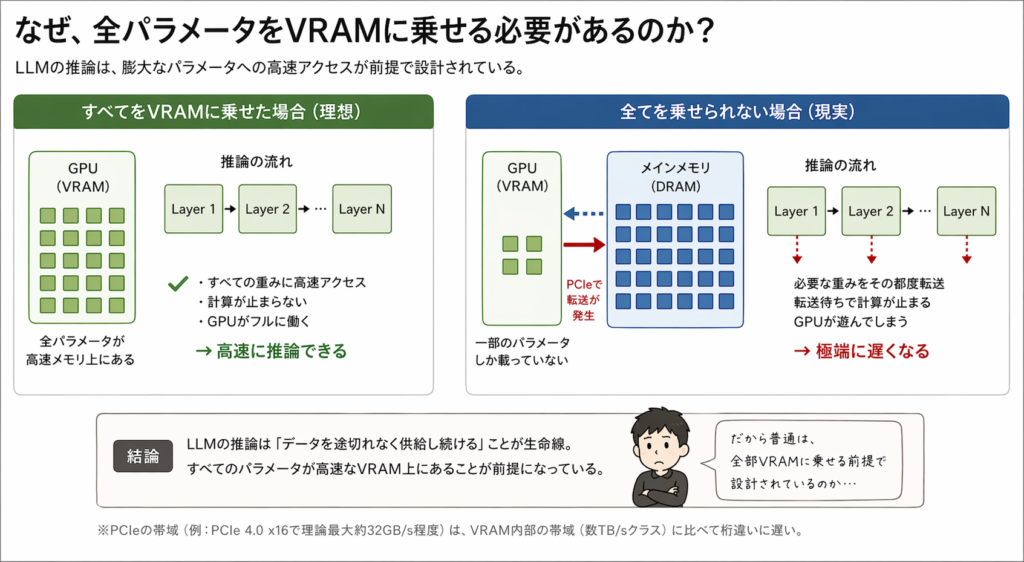
なぜ、全パラメータをVRAMに乗せておく必要があるのか。
- VRAMは高速だけど高価
- DRAMは遅いけど安価
CPUとメモリと同じ構造にできるはずだ。
- よく使うものだけVRAM
- 残りはDRAM
必要になったら持ってくる。理屈としては正しい。
必要になってからPCIeで転送したら終わる。
じゃあ、先に持ってくればいい。
■ なぜ全部をVRAMに乗せる必要があるのか
とりあえず非同期で先読みしてみた
- 計算と転送を並列で走らせる
- 今のレイヤー計算中に次を転送
動いた。
でも速くならなかった。
動く、でも速くならない
latency: 842 ms/token gpu_util: 82% pcie_rx: 11.8 GB/s (非同期なし) latency: 861 ms/token gpu_util: 61%
リソースは使っているのに結果が変わらない。
compute: 410 ms transfer: 390 ms idle: 370 ms
重なっているのに、隠せていない。
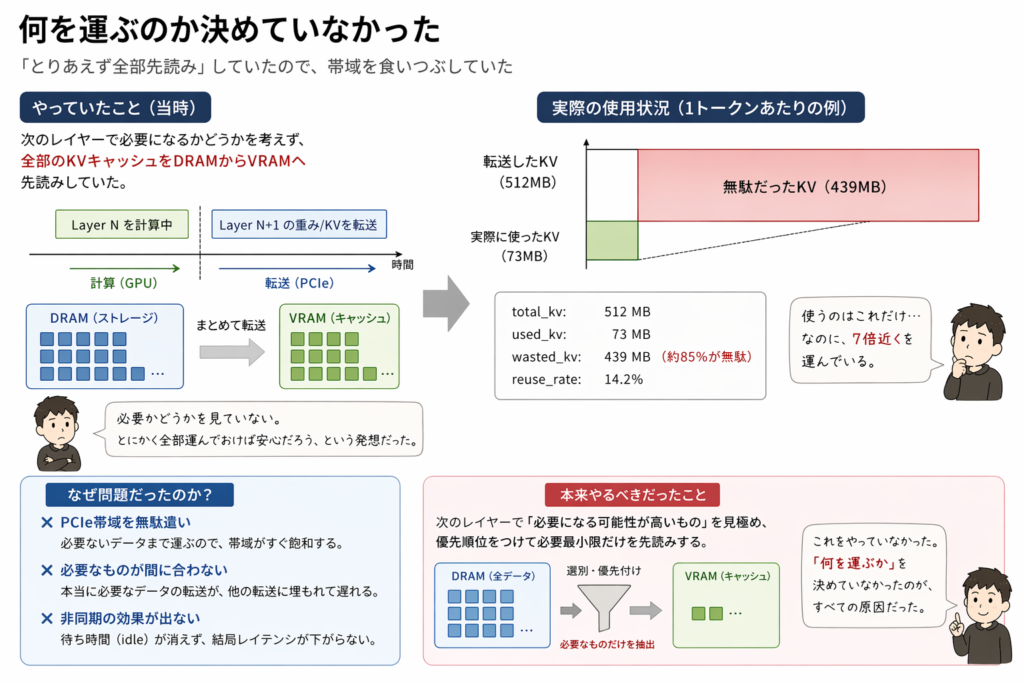
total_kv: 512 MB used_kv: 73 MB
使う量の7倍を運んでいる。
「何を運ぶか」を決めていなかった。
■ 無駄転送の実態
ヒューリスティック迷走期
Attention
hit: 68% miss: 32%
3回に1回外す。
履歴
安定するが崩れる。
距離
短文OK、長文崩壊。
N固定
N=32 → 遅い N=64 → 速い N=128 → 遅い
最適値が固定できない。
全部混ぜる
latency: 752 ms variance: ±180ms
平均は良くなる。でも安定しない。
どれもそれっぽい。でも決め手にならない。
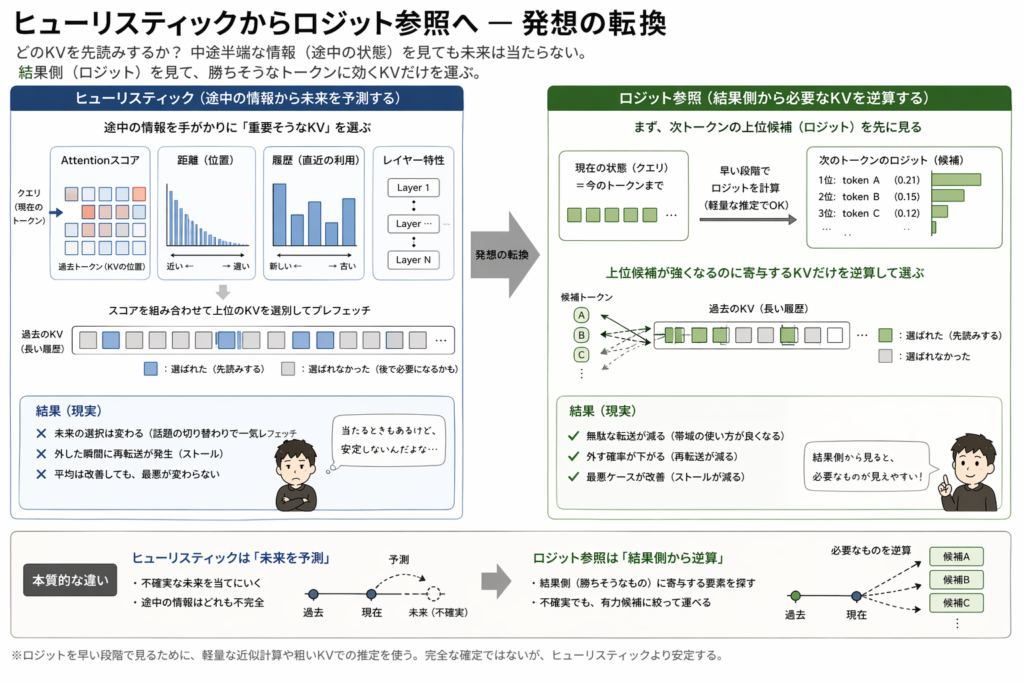
未来を予測している。
当たると速い。でも外すと全部崩れる。
平均は良くなる。でも最悪が変わらない。
ロジット参照という発想
未来は当たらない。だったら結果を見る。
Before: KV → Attention → ロジット After: ロジット → KV
kv_transfer: 512MB → 140MB latency: 780 → 610 ms
帯域が意味のある転送に変わる。
worst: 980 ms
一度外すと全部戻る。
初めて「何を運ぶか」が定義できた。
■ ヒューリスティック → ロジット参照
多少改善した、でも別の壁
- VRAM = キャッシュ
- DRAM = ストレージ
DRAMの価格が爆上がりした。
設計の前提が崩れる。
次は上下分離と圧縮解凍の話になる。


コメント